分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |
英伟达开源3400亿参数模型Nemotron-4 340B
第一财经 2024-06-15 15:05:57
作者:一财科技 责编:刘佳
AI帮你提炼, 10秒看完要点
智能挖掘相关板块, 定位投资机会


AI速读
节省{{readTime}}分钟阅读时间 {{aisd}}
AI生成 免责声明
开发人员可使用该系列模型生成合成数据。
当地时间6月14日,英伟达开源Nemotron-4 340B(3400亿参数)系列模型。据英伟达介绍,开发人员可使用该系列模型生成合成数据,用于训练大型语言模型(LLM),用于医疗保健、金融、制造、零售和其他行业的商业应用。
Nemotron-4 340B包括基础模型Base、指令模型Instruct和奖励模型Reward。英伟达使用了9万亿个token(文本单位)进行训练。Nemotron-4 340B-Base在常识推理任务,如ARC-c、MMLU和BBH基准测试中,可以和Llama-3 70B、Mixtral 8x22B和Qwen-2 72B模型媲美。

举报
第一财经广告合作,请点击这里
此内容为第一财经原创,著作权归第一财经所有。未经第一财经书面授权,不得以任何方式加以使用,包括转载、摘编、复制或建立镜像。第一财经保留追究侵权者法律责任的权利。如需获得授权请联系第一财经版权部:banquan@yicai.com
文章作者

相关阅读
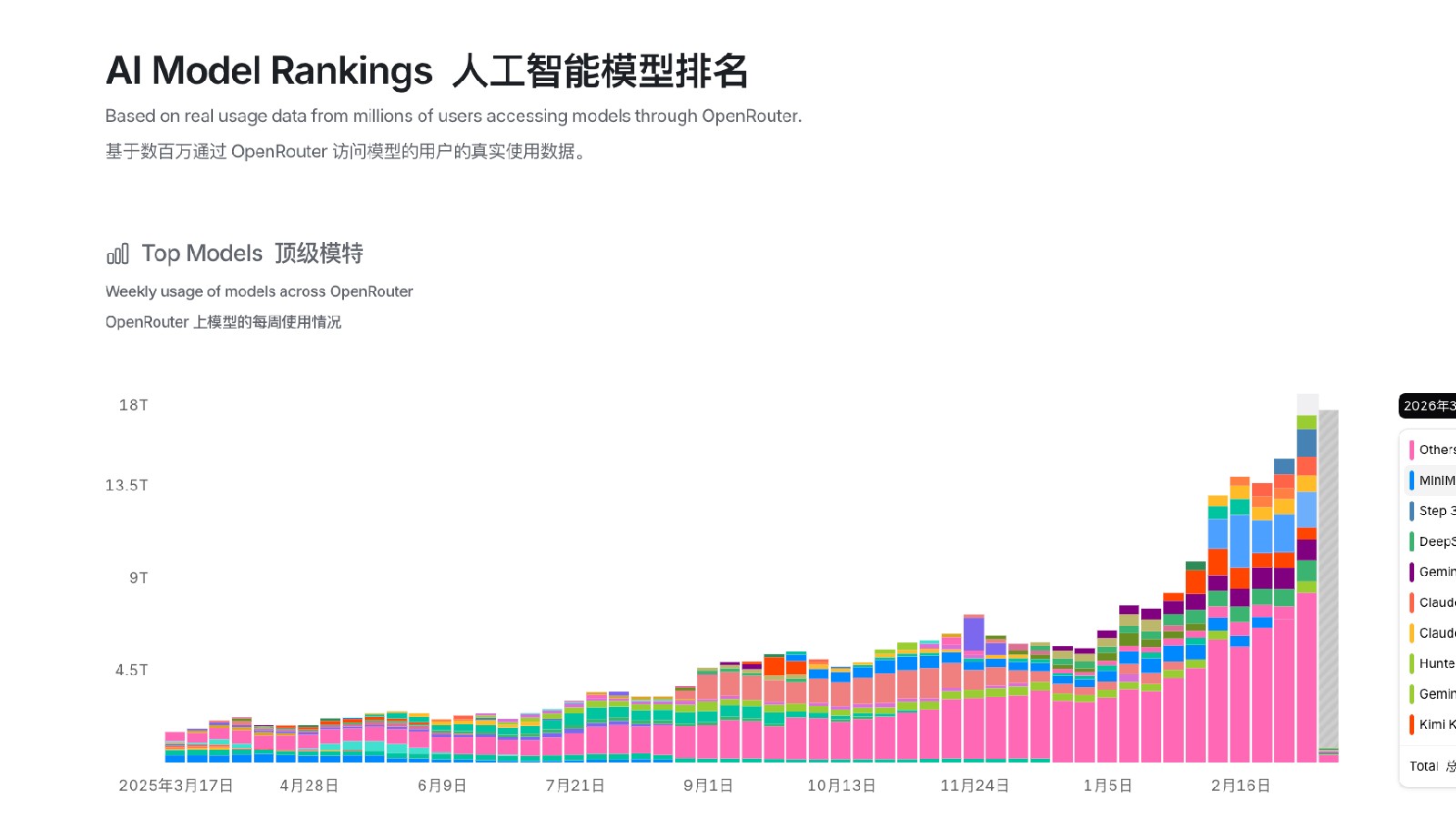
一周上涨超11%,国产大模型周调用量再超美国
全球模型调用量排名前九名中,国产模型占四位。

AI周报 | 阿里通义千问负责人离职;腾讯楼下千人排队安装OpenClaw
MiniMax发布上市后首份成绩单;OpenAI发布大模型GPT-5.4。

美团旗下AI浏览器两次回应代码风波:将升级代码审查流程
未来行业或许还会出现不少类似的争议或者不规范现象,可以将本次事件作为行业开源合规的警示案例。

AI周报 | 微信屏蔽元宝、千问红包链接;马斯克宣布SpaceX收购xAI
英伟达CEO黄仁勋称AI将改变工厂;OpenAI发布编程智能体。

AI周报| DeepSeek新模型曝光;马斯克炮轰ChatGPT诱导自杀
王小川隔空回应张文宏;OpenAI靠API业务月增超10亿美元收入。
一财最热