分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |



{{aisd}}
AI生成 免责声明
6月17日,沉寂已久的六小龙之一MiniMax酝酿了一个大动作,宣布将连续五天发布重要更新。今天第一弹是开源首个推理模型MiniMax-M1。

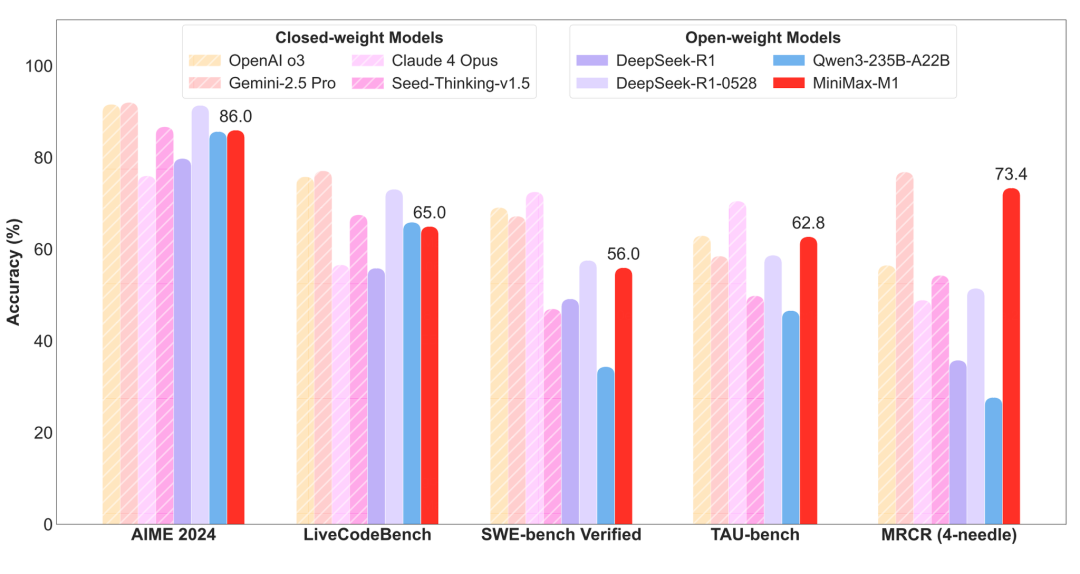
根据官方的报告,MiniMax-M1多项基准测试比肩DeepSeek-R1、Qwen3等开源模型,接近海外的最领先模型。
官方博客还提到,基于两大技术创新,MiniMax-M1训练过程高效得“超出预期”,只用了3周时间、512块H800 GPU就完成强化学习训练阶段,算力租赁成本仅53.47万美元。这比一开始的预期少了一个数量级。
多位开发者已经第一时间展开测评。前illasoft技术总监@karminski在社交平台发布了自己对MiniMax-M1的测评,认可其是“开源MoE第一梯队”。
@karminski着重测试了MiniMax-M1-80K的写代码能力,用“拆烟囱”这一编程案例实测发现,MiniMax-M1-80K在提示词下一次过,他提到DeepSeek-R1-0528 甚至 Gemini-2.5-Pro 都没能一次通过,这可能得益于其“训练材料足够新”和“思考时多次反刍成功避坑”的能力。

缺点是,从生成的前端页面来看, 样式不是很美观,因此用来生成高度创意的内容可能会面临不够发散的问题, 但反过来编程的指令遵循和精确性会更好。另外光影效果不是很好,也是训练不足的地方。
也有网友提到,测试发现MiniMax-M1模型中文写作是严谨优先的,幻觉较低,以遵循文本和指令为第一。这在注重发散的国内模型中比较难得。
MiniMax-M1这一新模型最大的亮点还是100万的上下文窗口长度,和闭源模型里的谷歌 Gemini 2.5 Pro一样,是DeepSeek R1的 8倍。
依托这一基础,M1系列在长上下文理解任务中 (MRCR)表现较优,从测试指标看,超越了所有开源权重模型,甚至超越海外的顶尖模型OpenAI o3和Claude 4 Opus,全球排名第二,仅微弱差距落后于Gemini 2.5 Pro。
“无限长的长文本能力是MiniMax团队一直在打磨的重要维度,对于做社交应用、情感陪伴应用,Agent等来说是很关键的技术。”云启资本合伙人陈昱在6月的大会论坛上表示。云启是MiniMax的天使轮投资机构。
TAU-bench是一个评估AI智能体在真实世界环境中可靠性的基准测试,在这一指标中,MiniMax-M1表现较为出色,超越了DeepSeeK-R1-0528和谷歌的Gemini-2.5 Pro,在全球仅次于OpenAI o3和Claude 4 Opus。
在代码能力(SWE-bench)上,MiniMax-M1显著超越大部分开源模型,仅微弱差距次于DeepSeek最新发布的R1。
MiniMax表示,MiniMax-M1的长文本能力得益于闪电注意力机制为主的混合架构,这一架构使得M1在进行长文本的上下文输入和深度推理时均有算力效率优势。MiniMax举例称,在用8万Token深度推理的时候,只需要使用DeepSeek R1约30%的算力。
除此之外,MiniMax提出的另一创新是强化学习算法CISPO。官方博客表示,在数学AIME的实验中,这比字节近期提出的 DAPO 等强化学习算法收敛性能快了一倍,显著优于 DeepSeek早期使用的 GRPO。这也是最终算力成本不到54万美元的原因。
因为相对高效的训练和推理算力使用,MiniMax的定价性价比较高,官方直接对标性价比之王DeepSeek喊话,“两种模式都比 DeepSeek-R1 性价比更高,另一种模式DeepSeek模型不支持。”
MiniMax-M1的定价采用阶梯式,随输入长度增加而提高:
0-32k 输入:输入 0.8元/百万token,输出 8元/百万token
32k-128k输入:输入 1.2元/百万token,输出 16元/百万token
128k-1M 输入:输入 2.4元/百万token,输出 24元/百万token
几乎与MiniMax同时,六小龙之中的另外一家月之暗面也在今日开源了编程模型 Kimi-Dev-72B。根据官方发布的信息,这一模型是基于阿里云的Qwen2.5-72B 微调得到的。根据报告,这一模型在SWE-bench编程基准测试中取得了全球最高开源模型水平,成绩超过了新版DeepSeek-R1。
不过,@karminski测试发现,“同样是生成拆烟囱demo, Kimi-Dev-72B生成的代码,用 Claude-4-Sonnet修改了3个bug 才能运行。”此外,这一案例基本需要600-800行代码才能完成, Kimi-Dev-72B只生成了220行, 较多细节都没有实现。
这引发了对其高分是否源于“过拟合”的质疑,这是机器学习中的常见问题,指模型在训练集上表现优异,但在未见过的新数据上预测能力显著下降。目前月之暗面尚未发布详细技术报告。
DeepSeek在年初搅动风暴后,AI六小龙有的出现高管出走风波,有的沉寂已久,埋头训练半年,看起来这些厂商已经做好了新的准备,继续加入这场大模型之争中。
MiniMax预告,后续四天将有更多更新。此前“海螺02(0616)”视频模型已现身AI视频竞技场,并取得第二名的佳绩,业界普遍预期海螺新版本即将正式亮相。如果海螺能延续M1在成本或能力上的突破,或将进一步搅动多模态AI的格局。
如需获得授权请联系第一财经版权部:banquan@yicai.com
文章作者


3天集聚4.5万人,全球开发者“花式”守护“养虾”安全
上海以全国10%的智算供给能力,运营全国首个语料公共服务平台,发布150余款的备案大模型,人形机器人的出货量全球领先,多款智能的芯片取得了突破。
靠AI一年收入38亿,美图创始人:大模型吞噬应用不成立
“不做通用大模型的投入”,是美图最关键的决策之一。

博鳌热议中国创新“新变化”,国际竞争转向水平型分工
开辟了许多意想不到的新赛道。

梁文锋曾婉拒投资,陈天桥砸十亿美元亲自下场!已投超百个AI项目
AI不应该只是通过预测下一个词该说什么来“写”出答案,而应该通过观察真实世界来“推导”出答案。他希望打造一个能像科学家一样追寻真相、逻辑严密、不出差错的“智慧大脑”。

AI进化速递 | 腾讯QClaw微信入口全面升级
MiniMax发布新一代大模型M2.7;OpenAI推出GPT-5.4 mini与nano。