分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |



{{aisd}}
AI生成 免责声明
在智能体时代,业界已经不再追逐参数越来越大的旗舰模型了,而是推出更多更快更省的小模型。
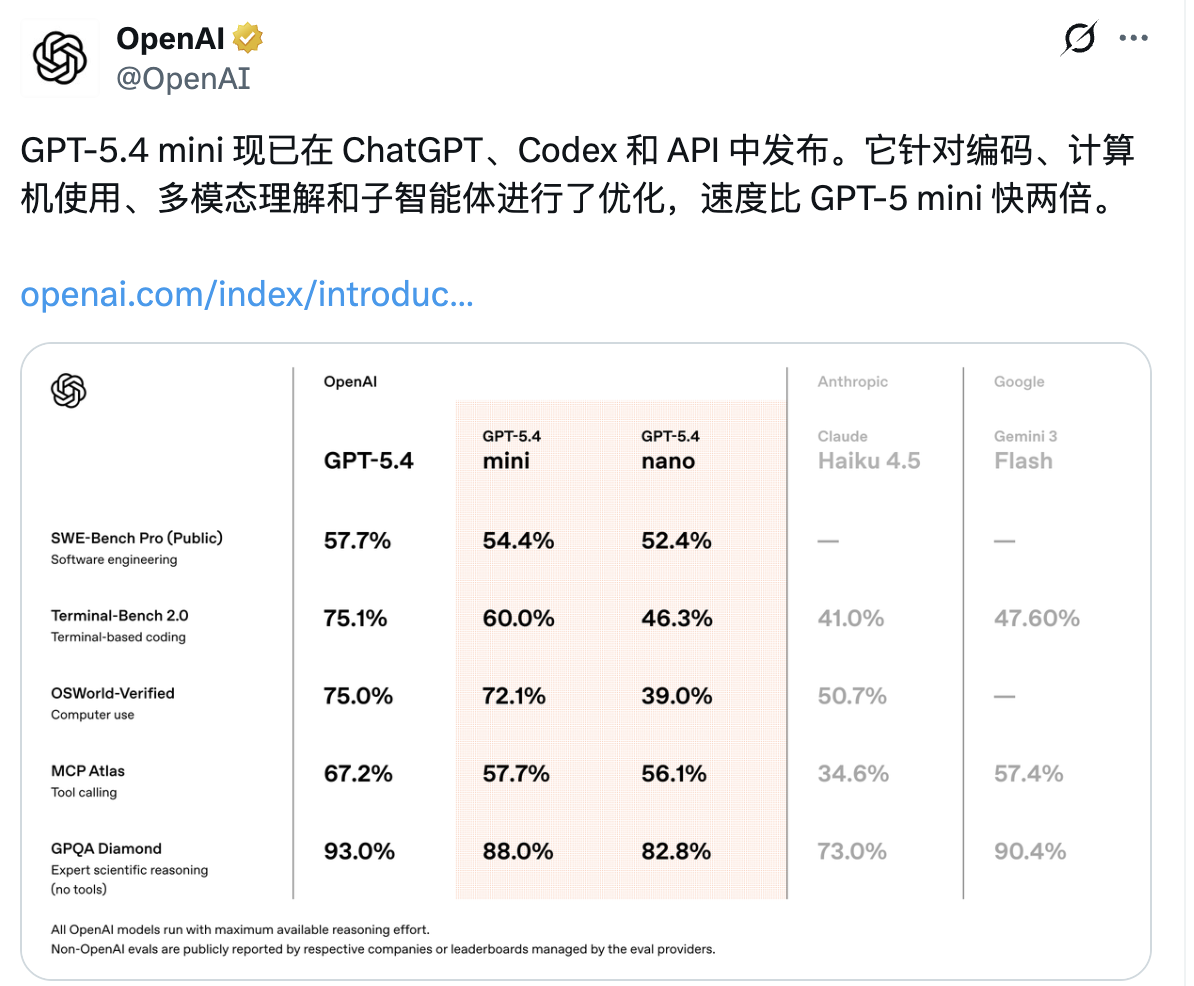
北京时间3月18日,OpenAI宣布推出两款小模型GPT‑5.4 mini与nano,官方称这是内部“迄今为止能力最强的小模型”,其能力接近旗舰模型GPT-5.4,但针对高频工作负载做了优化,旨在以更低延迟和更高性价比,为智能体时代的应用提供新选项。
行业分析认为,这是OpenAI补齐智能体时代产品拼图的关键一步。在AI进入真实业务后,并非每个环节都需要“杀鸡用牛刀”。此次发布的小模型,正是用在执行层,作为子智能体的主力。
然而,若单纯讨论性价比,这片战场早已硝烟弥漫,尤其中国的头部模型占据主导。海外就有开发者表示,GPT-5.4 mini“发布即失败”,因为中国的Kimi-K2.5模型不仅价格更低,表现也更优。但也有观点认为,基准测试的参考价值正在下降,真正的胜负还需在实际任务中检验。
OpenAI的智能体“组合拳”
OpenAI此次发布的两款小模型定位清晰,分工明确。
GPT-5.4 mini主打“速度与性能的平衡”,其运行速度是前代的两倍以上,在多项评估中性能接近旗舰模型,针对编码、计算机使用、多模态理解和子智能体进行了优化。而GPT-5.4 nano则是最小、最便宜的GPT-5.4系列版本,性能略逊于GPT-5.4 mini,适合较轻的任务。
OpenAI公布的评测数据显示,GPT-5.4 mini在编程及多模态任务上的表现突出。在编程基准SWE-bench Pro上,mini得分54.4%,与GPT-5.4的57.7%接近。在计算机操控基准OSWorld-Verified上,mini以72.1%的分数接近GPT-5.4的75%;在通用智能测试GPQA Diamond中,mini得分88.0%,与GPT-5.4的差距在5%左右。
与此同时,GPT-5.4 nano在各项分数上接近GPT-5.4 mini,尤其在编程和通用智能上表现较为出彩,较前代模型整体有所提升。
在具体应用中,OpenAI表示,GPT‑5.4 mini为延迟敏感的应用场景打造,在这类场景中,响应速度直接关系到产品体验:例如需要即时响应的代码助手、能快速完成辅助任务的子智能体、可捕捉并解析截图的计算机使用系统,以及能够实时推理图像的多模态应用。
“在这些设定下,最好的模型通常不是体量最大的那个,而是能够快速响应、可靠调用工具,并能在复杂专业任务中保持出色表现的模型。”OpenAI称,GPT‑5.4 mini在编程工作流中,实现了性能与延迟之间的最优权衡。
定价方面,GPT‑5.4 mini为每百万token输入0.75美元/输出4.5美元。OpenAI指出,这款mini 模型“仅消耗GPT-5.4配额的30%,让开发者能在Codex 中以约三分之一的成本处理简单编程任务”。此外,Codex 还可将任务委托给GPT-5.4 mini子智能体,从而让推理强度较低的工作在低成本模型上运行。
GPT‑5.4 mini支持400K上下文窗口,可以在API、Codex 及 ChatGPT 中调用,但另一个小模型GPT-5.4 nano仅通过API供开发者调用,专为对速度和成本要求极高的任务而设计。OpenAI建议开发者将其用于分类、数据提取、排序,以及作为处理简单辅助任务的子智能体。
GPT-5.4 nano定价为每百万token输入 0.2美元/输出token 1.25美元,价格约为mini的1/4。
行业认为,OpenAI此次动作的意义远大于发布两款小模型。这一战略意味着,在AI进入真实业务之后,模型分层会越来越重要。未来应用企业和开发者看的并不是用了哪个最强模型,而是如何搭建模型系统,将不同成本和能力的任务分配给合适的模型。
甚至有行业人士认为,OpenAI更像是专门为当下爆火的OpenClaw推出新的模型,因为新模型适合高频工具调用、本地环境感知、多步自主执行的任务。
性价比打不过国产模型?
在当前的智能体系统搭建中,不少开发者都会选择用一个较贵、表现较好的旗舰大模型作为“大脑”来做任务的整体规划,应对复杂、难以决策的场景,然后将高频且简单的执行工作分配给小模型,可以大规模地快速完成。
当前行业的共识是,以OpenClaw代表的智能体生态非常消耗Token,往往一个简单的任务就能花掉不少成本。因此,未来真正进入企业流程的,不会只有一个最强的模型,也需要几个性价比模型。
在官方博客中,OpenAI也表达了类似的观点,未来开发者无需再用单一模型处理所有事务,而是构建一种组合系统:由大模型决定任务方向,小模型则进行大规模快速执行。
“GPT‑5.4 mini非常适合那些结合了不同规格模型的系统。例如在Codex 中,GPT‑5.4 这种体量较大的模型负责处理规划、协作和最终判定,同时将具体的子任务并行分配给GPT‑5.4 mini子智能体,可以做的工作包括搜索代码库、审阅大文件或处理辅助文档。”OpenAI称。
据第一财经记者了解,在智能体系统中,不少开发者目前首选的“大脑”模型是海外的Claude 4.6 Opus、GPT-5.4 Pro、或Gemini 3.1 Pro,但作为子智能体的主力模型,则倾向于国产的模型,价格便宜,且性能够用。
如果比拼性价比,OpenAI的新模型会比中国的模型更好吗?
AI基准测试机构ArtificialAnalysis整理的一份大模型性价比排行榜可以作为参考,横轴是大模型的价格,竖轴是大模型的智能指数得分,象限的右上角绿色区域则是综合了智能与价格的性价比模型。可以看到,包括DeepSeek V3.2、MiniMax-M2.5等都在性价比较优的区间,此外Kimi、智谱的模型也接近这一象限。
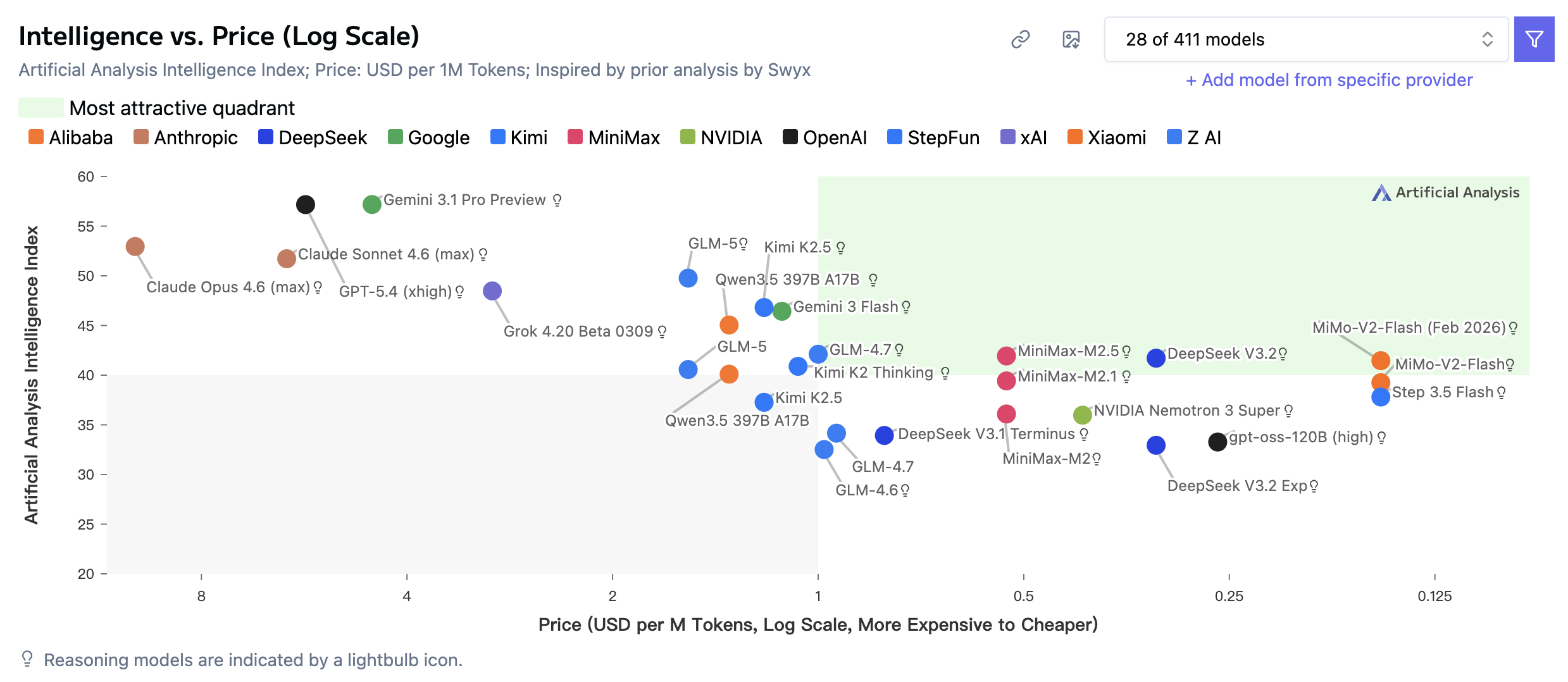
具体价格对比来看,GPT‑5.4 mini为每百万token输入0.75美元/输出4.5美元。根据ArtificialAnalysis的数据,性价比较高的DeepSeek V3.2每百万token输入0.28美元/输出0.42美元,输出价格是GPT‑5.4 mini的1/10;MiniMax M2.5则为每百万token输入0.3美元/输出1.2美元,输出是GPT‑5.4 mini的1/4;而Kimi-K2.5的价格为每百万token输入0.6美元/输出3美元,也小于GPT‑5.4 mini的定价。
即便与海外谷歌的快速版模型Gemini 3 Flash(输入0.5美元/输出3美元)相比,GPT‑5.4 mini也并没有优势。因此,若要做廉价平替,OpenAI新模型的竞争力或许不太够。
有开发者提出“GPT-5.4-mini推出就失败了,因为Kimi-K2.5更便宜”的观点,引起了不少讨论,同时也有反驳的声音。有开发者指出,基准排名对于实际工作流程正变得越来越没有参考价值,没有具体实践过还不能下定论。
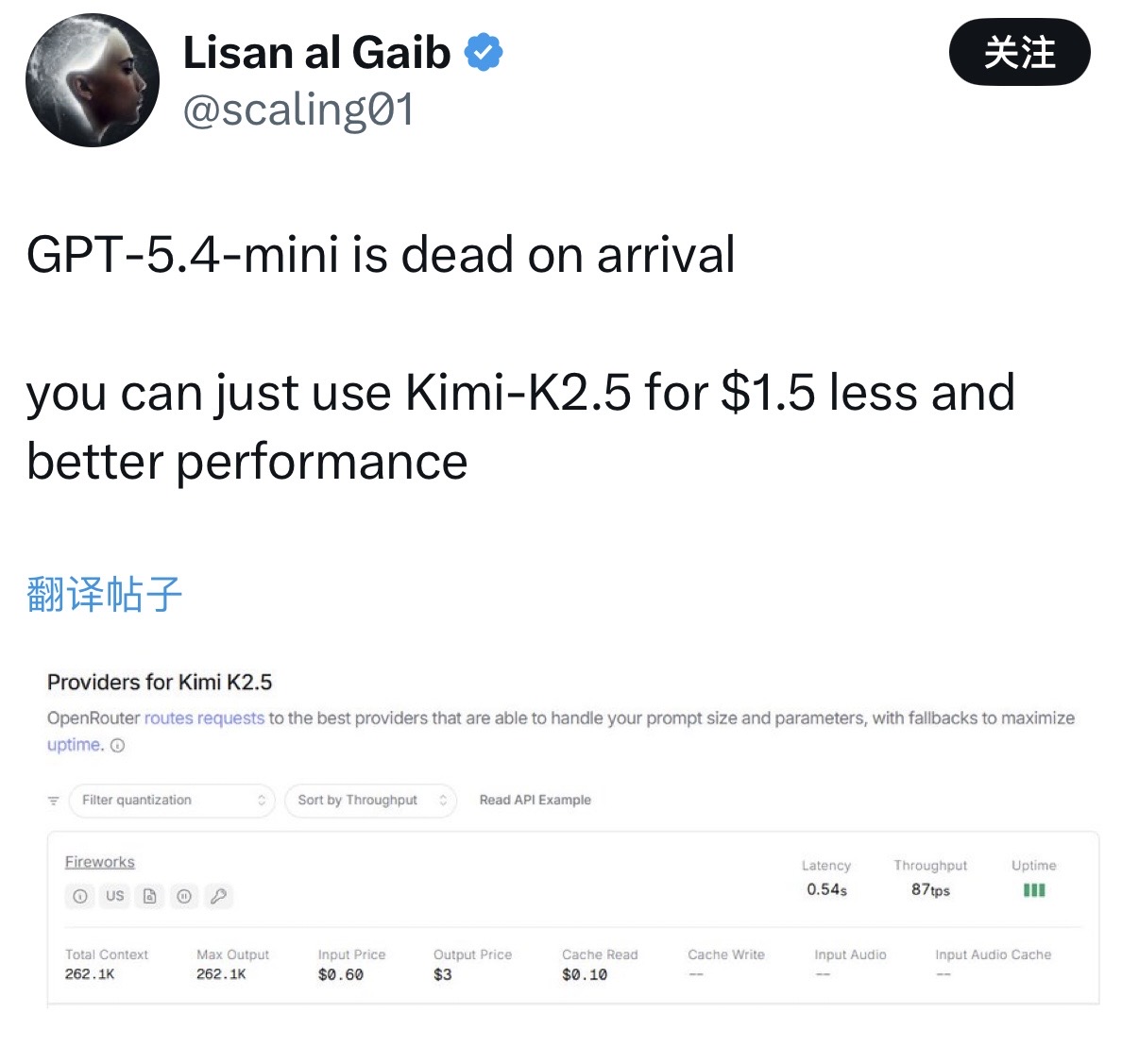
“对我来说,模型最重要的是:与我的工具集成效果如何、真的能节省生产时间吗、如果遇到极端情况会发生什么?”上述开发者认为,最好的模型并不是排名最高的,而是凌晨两点需要它的时候它不会坏掉的。
另一名开发者也认为,小模型的价格竞争异常激烈,但基准测试得分并不能反映实际任务中的可靠性。“一款价格便宜95%但可靠性降低5%的机型,实际上可能因为重试和调试时间而付出更高的代价。”
由此来看,开发者更为看重的还是模型在真实业务场景中的能力、稳定性与集成体验。GPT-5.4 mini到底是OpenAI补齐智能体版图的关键拼图,还是这场性价比大战中的失败者,答案还得看开发者。
如需获得授权请联系第一财经版权部:banquan@yicai.com