分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |
大模型书生·浦语再开源,推出200亿参数版本
第一财经 2023-09-20 19:45:00
作者:一财科技 责编:刘佳


{{aisd}}
AI生成 免责声明
9月20日,上海人工智能实验室宣布与商汤科技联合香港中文大学和复旦大学正式推出书生·浦语大模型(InternLM)200亿参数版本InternLM-20B,并在阿里云魔搭社区(ModelScope)开源首发。同时,书生·浦语面向大模型研发与应用的全链条工具链升级,与InternLM-20B一同继续全面开放,向企业和开发者提供免费商用授权。

上海人工智能实验室是人工智能领域的新型科研机构,主要开展战略性、原创性、前瞻性的科学研究与技术攻关。在大模型的应用价值日趋受到关注的背景下,上海人工智能实验室联合多家机构推出中量级参数的 InternLM-20B 大模型,其重点在于性能先进且应用便捷,以不足三分之一的参数量,达到了当前被视为开源模型标杆的Llama2-70B的能力水平。
自今年6月首次发布以来,书生·浦语已历多轮升级,此次其发布的20B量级模型具备更为强大的综合能力,在复杂推理和反思能力上尤为突出,因此可为实际应用带来更有力的性能支持;同时,20B量级模型可在单卡上进行推理,经过低比特量化后,可运行在单块消费级GPU上,因而在实际应用中更为便捷。
在相对有限的参数规模下,研究人员在架构设计时面临重要的取舍——提高模型的深度还是宽度?通过广泛的对照实验,书生·浦语团队发现,更深的模型层数更有利于复杂推理能力的培养。因此在架构设计时,研究人员把模型层数设定为60层,而7B与13B模型通常采用32层或者40层设计;同时内部维度保持在5120,处于适中水平。通过架构设计上的新取舍,InternLM-20B在较高计算效率的条件下实现了复杂推理能力的显著提升。
相比于此前的开源模型,InternLM-20B的能力优势主要体现在更长的语境。通过外推技术,InternLM-20B支持16K语境长度,可以支持长文理解、长文生成和超长对话。
工具调用是拓展大语言模型能力边界的重要手段,也是OpenAI近期推出大模型的重点特性之一。InternLM-20B对话模型支持了日期、天气、旅行、体育等数十个方向的内容输出及上万个不同的 API。
如需获得授权请联系第一财经版权部:banquan@yicai.com
文章作者


OpenAI新动作!砸40亿美元成立新公司,不卷模型卷落地
AI “最后一公里”之战。

AI进化速递丨广东省人工智能应用对接大会举行
AI进化速递丨广东省人工智能应用对接大会举行
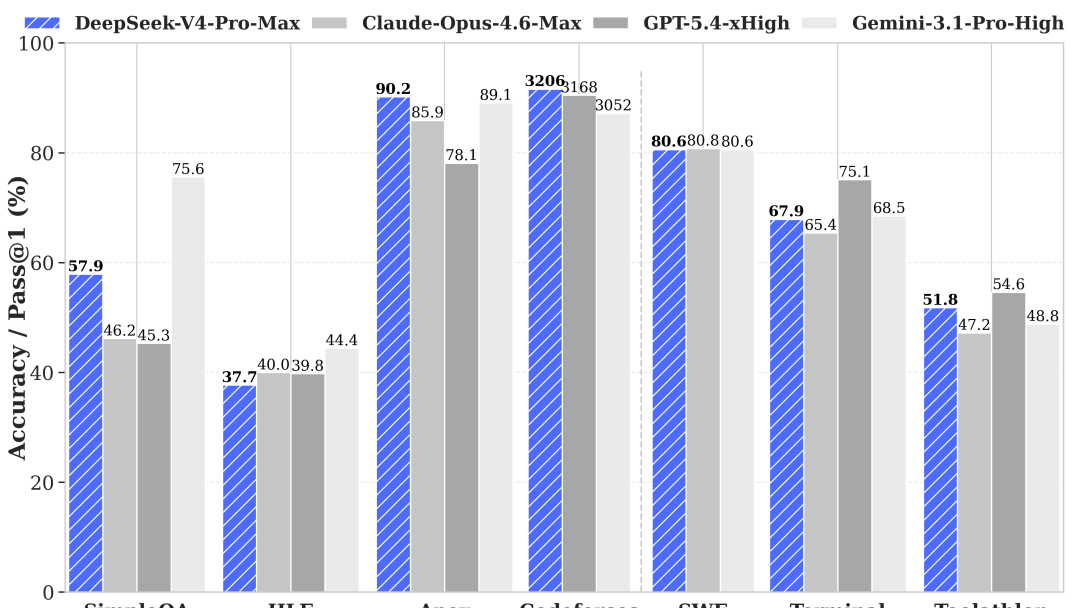
DeepSeek-V4来了!华为昇腾加持,还是那个“价格屠夫”
DeepSeek击败了所有开源模型,推理约落后前沿闭源模型3–6 个月。
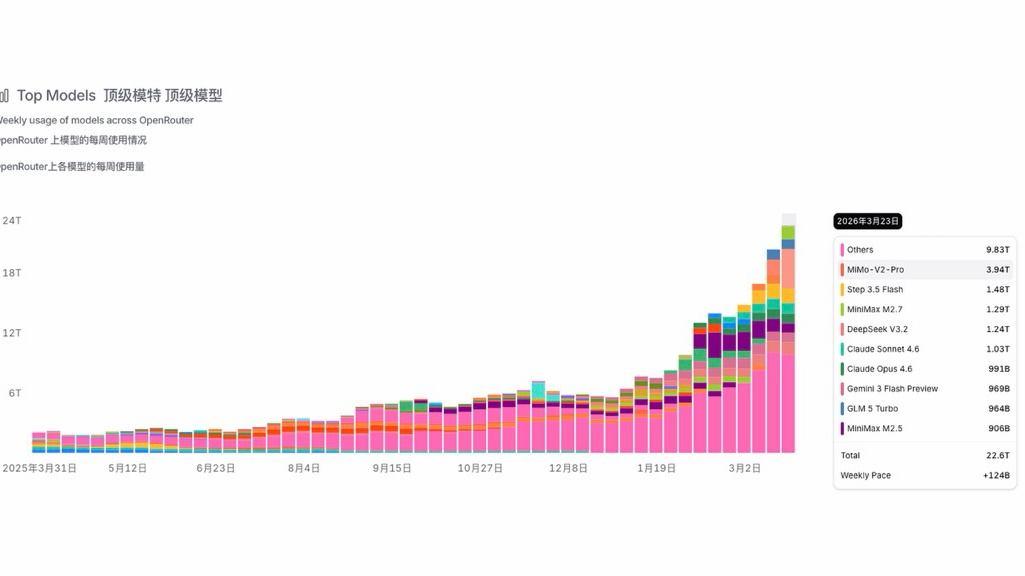
连续一个月霸榜!国产大模型调用量超越海外模型
OpenClaw是本轮Token消耗增长的核心驱动因素。

3天集聚4.5万人,全球开发者“花式”守护“养虾”安全
上海以全国10%的智算供给能力,运营全国首个语料公共服务平台,发布150余款的备案大模型,人形机器人的出货量全球领先,多款智能的芯片取得了突破。