分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |



{{aisd}}
AI生成 免责声明
DeepSeek又发新模型了,这次是一个OCR 模型。10月20日,DeepSeek在Github开源了这一新模型,并发布《DeepSeek-OCR:Contexts Optical Compression》(《DeepSeek OCR:上下文光学压缩》)论文,解释了这一成果。
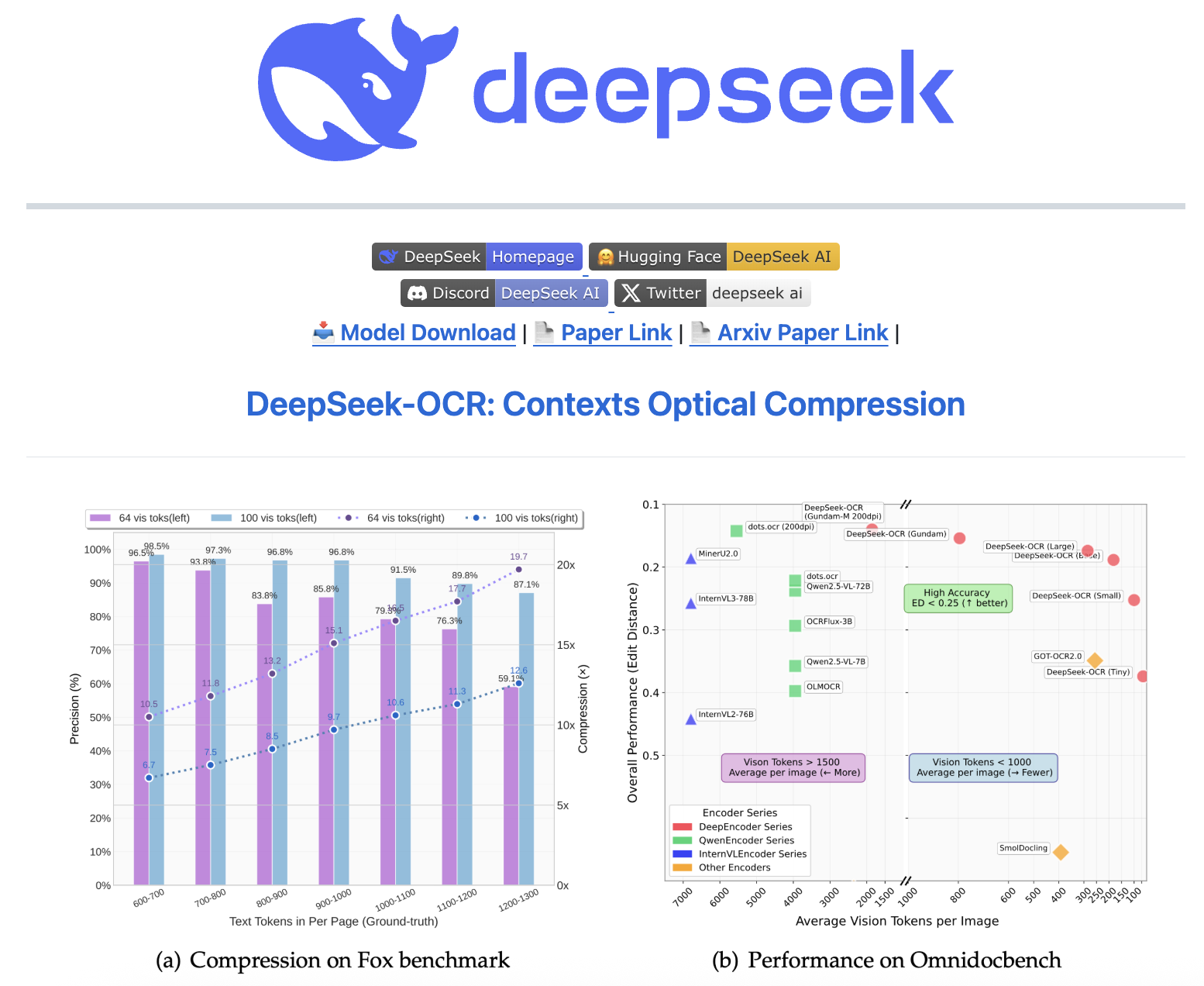
论文提到,当前的大语言模型在处理过程中面临着重大的计算挑战,文本内容过长,因此团队探索了一种具有潜力的解决方案:利用视觉模态作为文本信息的高效压缩介质。
具体来说,这一OCR模型可以将文本压缩成视觉模态,所谓“一图胜千言”,这样可以消耗更少的Token,测试显示,通过文本到图像的方法可以实现近 10 倍无损上下文压缩,OCR 准确率还能保持在 97% 以上。
论文提到,在实际应用中,单张A100-40G显卡,可支持每日20万页以上的大语言模型/视觉语言模型训练数据生成。
简单来看,团队的思路是,既然一张图就能包含大量文字信息,同时用的 Token 更少,那就可以将文本转成图像,这就是题目中提到的“光学压缩”,用视觉模态压缩文本信息。这一结果显示出该方法在长上下文压缩和大模型的记忆遗忘机制等研究方向上具有相当潜力。
DeepSeek-OCR由两个核心组件组成,其中DeepEncoder(编码器)负责图像特征提取和压缩,DeepSeek3B-MoE(解码器)负责从压缩后的视觉 Token 中重建文本。
解码器用的是 DeepSeek-3B-MoE 架构。虽然只有 3B 参数,但采用了 MoE(混合专家)设计,64 个专家中激活 6 个,再加 2 个共享专家,实际激活参数约 5.7 亿。这也让模型既有 30 亿参数模型的表达能力,又保持了5亿参数模型的推理效率。
实验数据显示,当文本 token 数量在视觉 token 的 10 倍以内(即压缩率小于10倍)时,模型的解码(OCR)精度可达 97%;即使在压缩率达到 20倍的情况下,OCR 准确率仍保持在约60%。
DeepSeek 团队在论文里还提出了具有想象力的未来——用光学压缩模拟人类的遗忘机制。人类的记忆会随时间衰退,越久远的事情记得越模糊,那是否AI也能这样?于是,团队设计将更久远的上下文,逐步缩小渲染图像的大小,以进一步减少token消耗。随着图像越来越小,内容也越来越模糊,最终达到“文本遗忘”的效果,就像人类记忆的衰退曲线一样。
论文中提到,这还是个需要进一步调查的早期研究方向,但这对于平衡理论上无限的上下文信息是一个很好的方法,如果真能实现,对于处理超长上下文将是个巨大突破。因此,这次发布的DeepSeek-OCR 表面上是个 OCR 模型,但从另一个角度来看,其研究代表了一个有前景的新方向。
有网友认为,这是一步好棋,人类就是阅读视觉文字,同时理解物理世界的时空概念,如果能统一语言和视觉,可能通向超级智能。
这一OCR模型发布不久就在GitHub获得超过1400颗星星。从论文署名来看,这一项目由 DeepSeek 三位研究员 Haoran Wei、Yaofeng Sun、Yukun Li 共同完成。行业消息显示,其中一作 Haoran Wei 曾在阶跃星辰工作过,曾主导开发了旨在实现“第二代 OCR”的 GOT-OCR2.0 系统,因此由其主导 DeepSeek 的 OCR 项目也在情理之中。
不过,DeepSeek迟迟不发R2这样的新模型,市场已经有一些声音认为其落后了,也有观点认为,DeepSeek目前只是在修炼“内功”,为下一代模型蓄力。
如需获得授权请联系第一财经版权部:banquan@yicai.com





