分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |



{{aisd}}
AI生成 免责声明
虽然“开源”一词并不是新事物,但DeepSeek的出现又让业内对大模型开源有了更多的探讨。
在22日举行的2025全球开发者先锋大会开幕式上,香港科技大学校董会主席、美国国家工程院外籍院士沈向洋在开始主旨演讲时称,如今大模型行业天天有新闻,过去两年涌现出大量了不起的AI技术、产品和应用。中国也在不断追赶人工智能前沿技术,而DeepSeek的横空出世,则让中国的大多数老百姓都知道了中国的人工智能做得有多好。

金叶子/摄
“DeepSeek做得非常好,重要的一个影响是把它开源,而在这之前 ,也有一些公司开源了大模型,诸如美国Meta的LLaMA、中国阿里的通义千问。”沈向洋说。
他介绍道,DeepSeek最近在国际上的影响非常大,它的出现是开源社区的胜利,把这样了不起的模型开源出来,能让更多人更多有机会在这样的模型上做更多了不起的事情。至于DeepSeek对整个大模型开源时代的影响,在他看来,中国已经从原来只是一个获益者变成一个今天在开源社区的贡献者。“大模型时代,开源并没有像以往那么多、那么快,我相信开源这件事情会越做越好。中国的团队、上海的团队一定会引领开源潮流”。
另外,他还提到了开源模型的商业模式。”怎么样可以在源代码不收费的情况下拥有一个商业模式?美国就有一家(开源解决方案)公司叫Red Hat Linux,提供更多的软件服务,它仍然可以做到几百亿美金市值,后来被IBM收购。”
沈向洋称,从大语言模型时代已有的市场份额看,诸如OpenAI、微软、亚马逊、谷歌等等,闭源模型的份额实际上还是远远超过(开源)的商业份额,但这件事情可能接下来一两年改变会非常大。“但开源和闭源之间,不需要完全是从对立的面来看,未来的商业模式,总是要想出一个平衡开源和闭源的方式。”
如需获得授权请联系第一财经版权部:banquan@yicai.com
文章作者


连续三周,国产模型调用量反超美国模型
中国开源模型大大降低了全球使用AI的门槛。

海外明星公司被曝“套壳”Kimi,国产开源渐成全球AI支柱
此次事件再次验证了中国开源模型们将成为全球AI发展的重要力量。

梁文锋曾婉拒投资,陈天桥砸十亿美元亲自下场!已投超百个AI项目
AI不应该只是通过预测下一个词该说什么来“写”出答案,而应该通过观察真实世界来“推导”出答案。他希望打造一个能像科学家一样追寻真相、逻辑严密、不出差错的“智慧大脑”。
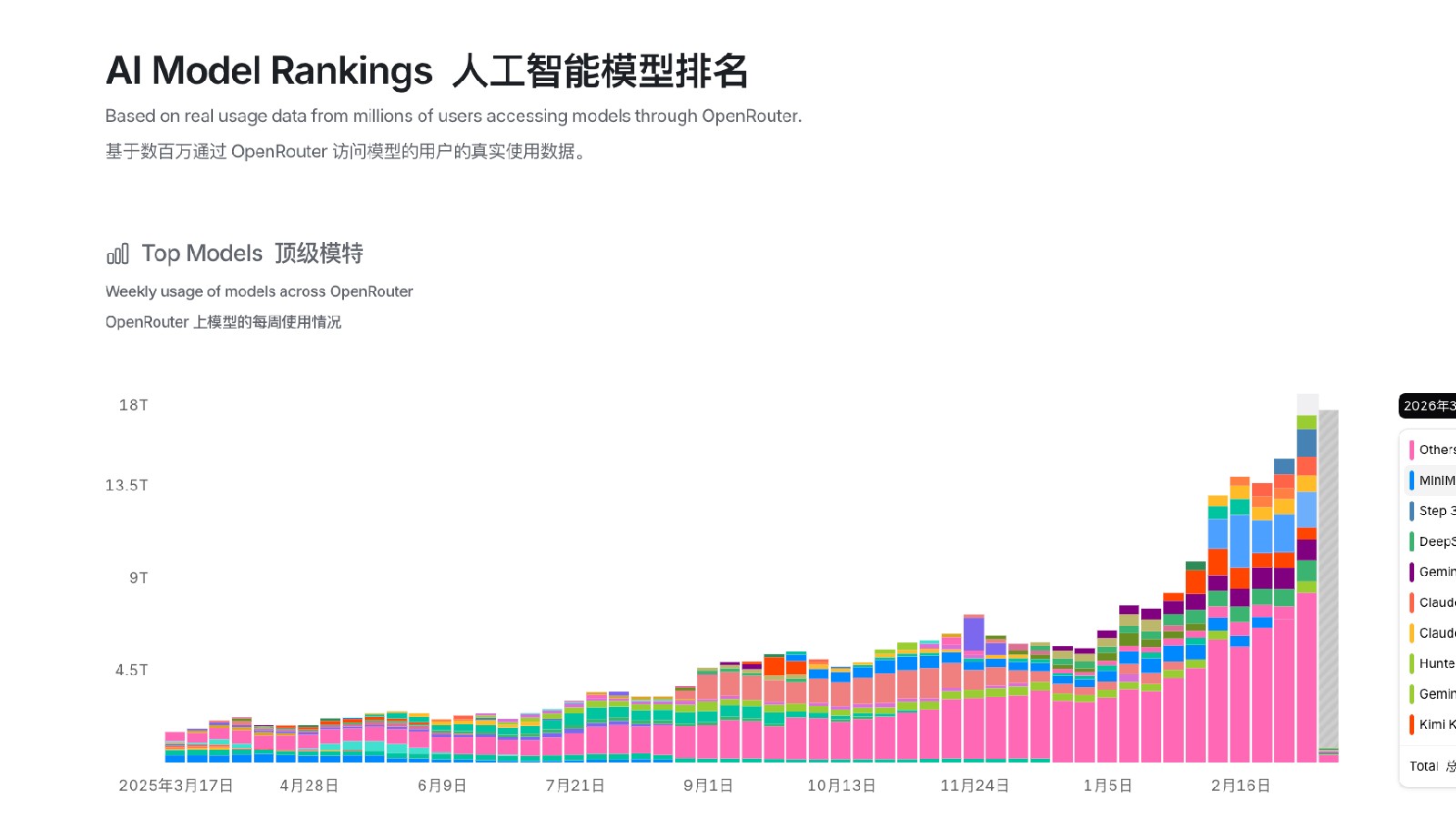
一周上涨超11%,国产大模型周调用量再超美国
全球模型调用量排名前九名中,国产模型占四位。

美团旗下AI浏览器两次回应代码风波:将升级代码审查流程
未来行业或许还会出现不少类似的争议或者不规范现象,可以将本次事件作为行业开源合规的警示案例。