分享到:
- 微信
- 微博
分享到微信打开微信,点击底部的“发现”, |



{{aisd}}
AI生成 免责声明
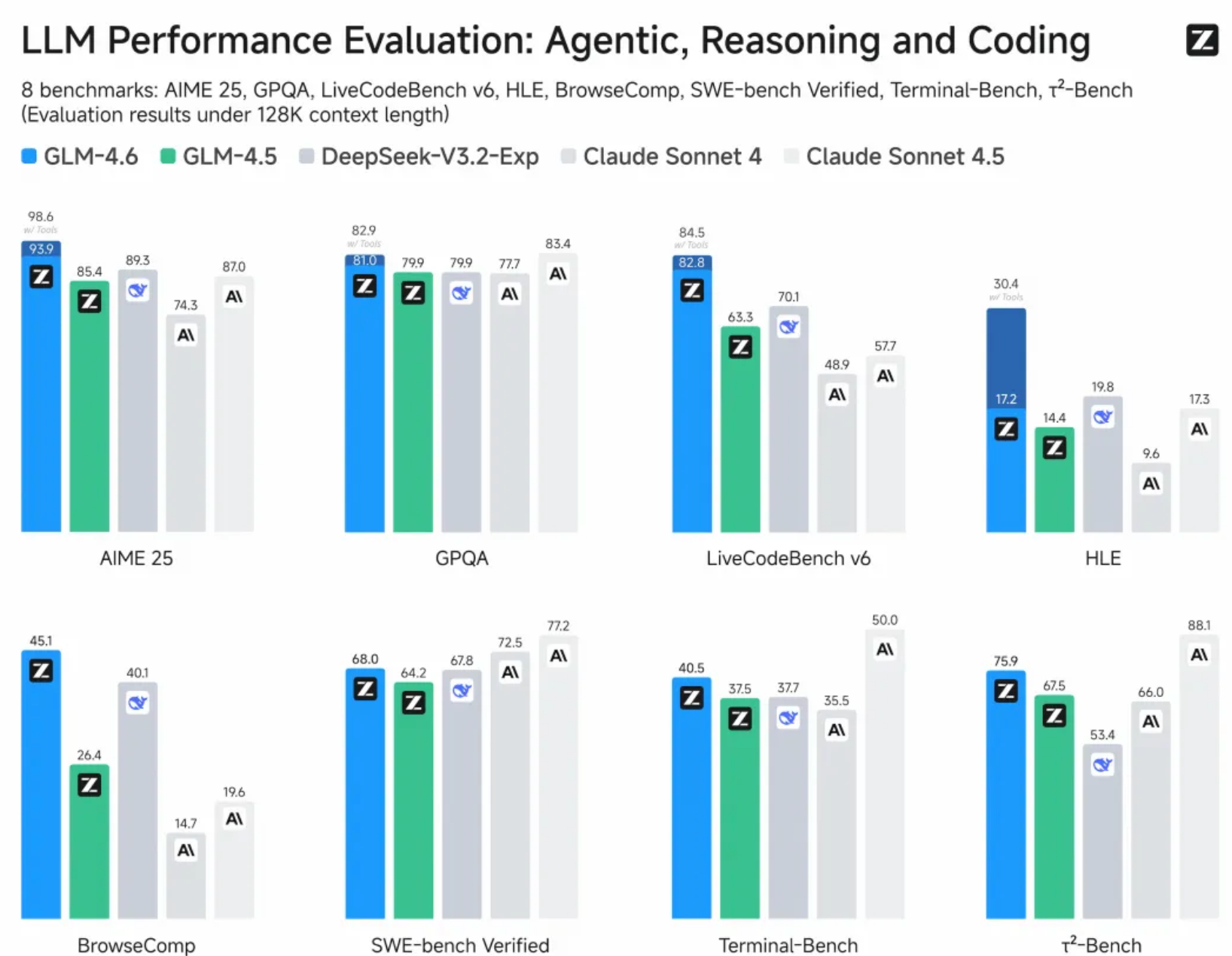
9月30日,国产大模型初创公司智谱发布GLM-4.6新模型。作为GLM系列最新版本,GLM-4.6在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个方面能力有所提升。
官方信息显示,此次升级表现在公开基准与真实编程任务中,GLM-4.6代码能力对齐Claude Sonnet 4;上下文窗口由128K提升至200K,适应更长的代码和智能体任务;新模型提升推理能力,并支持在推理过程中调用工具;搜索方面增强模型的工具调用和搜索智能体。
另外,“模芯联动”是此次新模型发布的重点,GLM-4.6已在寒武纪国产芯片上实现FP8+Int4混合量化部署,这也是行业首次在国产芯片上投产的FP8+Int4模型芯片一体解决方案,在保持精度不变的前提下,降低推理成本,为国产芯片在大模型本地化运行上探索可行路径。
FP8是8 位浮点数(Floating-Point 8)数据类型,动态范围广、精度损失小;Int4是4 位整数(Integer 4)数据类型,压缩比极高,内存占用最少,适配低算力硬件但精度损失相对明显。此次尝试的“FP8+Int4 混合” 模式,并非简单将两种格式叠加,而是根据大模型的“模块功能差异”,针对性分配量化格式,让该省内存的地方用Int4压到极致,该保精度的地方用FP8守住底线,实现合理资源分配。
具体到模型适配过程中,占总内存的60%-80%的大模型核心参数通过Int4量化后,可将权重体积直接压缩为FP16的1/4,大幅降低芯片显存的占用压力;推理环节积累的临时对话数据可以通过Int4压缩内存的同时,将精度损失控制在 “轻微”范围。而FP8可重点针对模型中“数值敏感、影响推理准确性”的模块,降低精度损失、保留精细语义信息。
除了寒武纪,据记者了解,摩尔线程已基于vLLM推理框架完成对GLM-4.6 的适配,新一代GPU可在原生FP8精度下稳定运行模型,验证MUSA架构及全功能GPU在生态兼容性和快速适配能力方面的优势。
寒武纪与摩尔线程此番完成对GLM-4.6的适配,标志着国产GPU已具备与前沿大模型协同迭代的能力,加速构建自主可控的 AI 技术生态。接下来,GLM-4.6搭配国产芯片的组合将率先通过智谱MaaS平台面向企业与公众提供服务。
如需获得授权请联系第一财经版权部:banquan@yicai.com
文章作者


晓数点丨一个月来频繁易主,A股又见新“股王”
一图速览>>

获利盘与解禁阴影交织,智谱5000亿市值后冲高回落
抛压大于买盘,前期获利盘集中兑现。

电子行业市值剑指20万亿里程碑,AI引爆产业跃迁
半导体与AI两大超级科技赛道,成为电子行业市值变迁核心推手的背后,是全球科技产业革命与中国制造升级的历史性交汇带来的经济结构变化,这一深层次变化更体现在电子行业占比A股总市值的提升。2016年1月,电子行业市值占比仅为3.41%,到2026年5月,这一比例已跃升至14.23%。
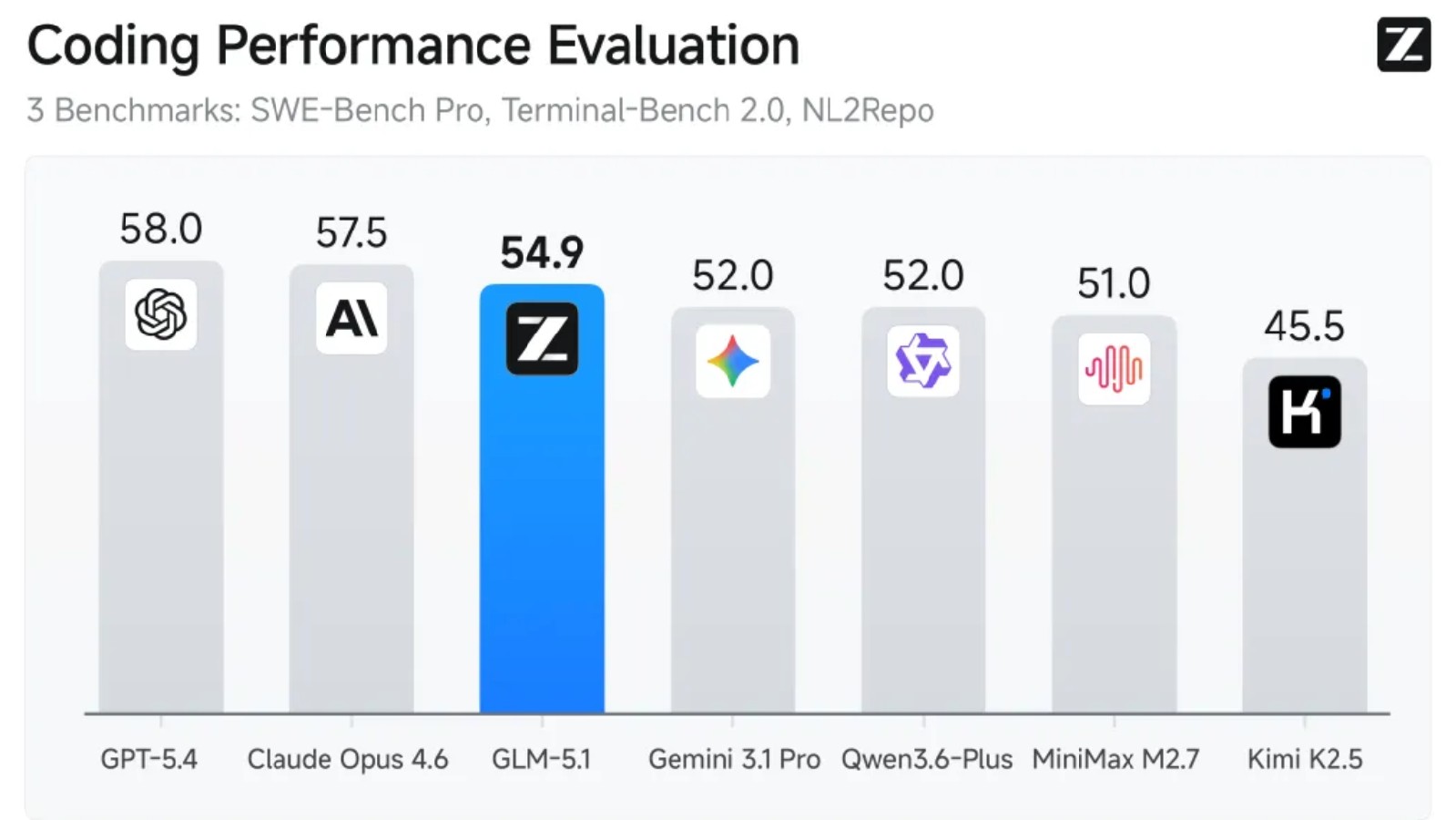
冲击全球开源最强席位,智谱发布新模型,再度提价10%
延长模型的“有效工作时长”是提升智能体能力的一个基础维度。
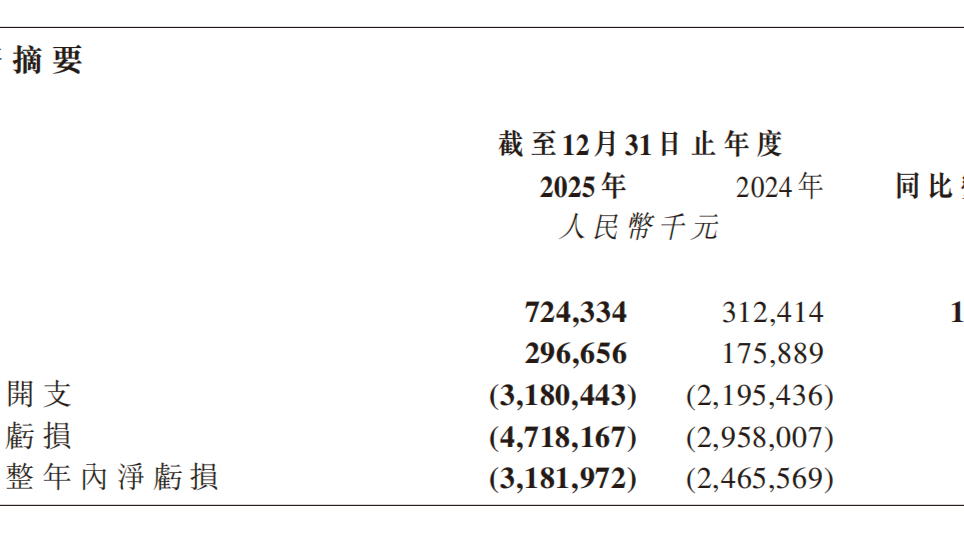
大模型第一股首份成绩单,智谱高层回应Token量价齐升可持续性
未来大模型标准化API能力将规模化放量。